Tech intern projects at Optiver Amsterdam

This summer, Optiver’s Amsterdam office hosted a group of tech interns eager to tackle the challenges of market making. Beyond just theory, they worked hands-on with our core trading technologies, directly engaging with some of the most interesting technical challenges in the financial industry.
In this blog post, four of our Software Engineering interns delve into their individual projects. Through their first hand accounts, gain insight into the challenges they faced, the knowledge they acquired and the innovative solutions they devised over just six weeks.
AMS tech intern projects
- Breaking free of a single process in Python
- Infrastructure as Code with Terraform and AWS
- Let’s make automation scalable
- Rewriting the IEX IML: A deep dive into low-latency trading systems
Breaking free of a single process in Python
Torin Felton, University of Manchester

Challenge
Researchers and traders at Optiver develop scripts that perform a variety of complex calculations to provide insights we actively trade on. These scripts utilise an in-house asynchronous Python framework called Amnis, which structures small computations into nodes on a directed acyclic graph (DAG), altogether forming a large computation. However, this design is constrained to a single process, resulting in slow performance for certain scripts with ~40,000 nodes and limited scaling.
Approach
My objective was to develop a multi-process scheduler for Amnis DAGs, enabling true parallelism, seriously boosting script speed, and establishing a foundation for large horizontal scaling in the future. For example, consider a DAG with a subset of nodes that are run for 20 underlying assets. With the current Amnis scheduler, these are computed asynchronously on a single thread. However, the ideal scenario is to do them all simultaneously – a critical requirement when scaling to hundreds or even thousands of underlying assets.
Developing a multi-process scheduler in Python for a large computation framework posed numerous challenges: selecting the best method for inter-process communication, managing and disposing of processes, and cross-process error handling to name a few. Additionally, plenty of open-ended conceptual problems arise: How do you decide which nodes go on each process? How do you provide good metrics to show the users if this assignment is optimal? How do you serialise the DAG correctly to send to each process on initiation?
Adding to the complexity, developing a multi-process scheduler may be arduous, but debugging one is even worse. A particular bug I’ve encountered stands out: a deadlock. Deadlock is like a never-ending traffic jam for processes, where everyone is waiting on another, and no one is moving. It took three days to track down and fix the section of code where this would occur, and this taught me some valuable lessons on why good logging of what your program is doing (and not doing) is extremely important.
Results
After getting the scheduler working, I tested it on an example DAG designed to illustrate the maximum potential benefit of multi-processing. Here are the results:
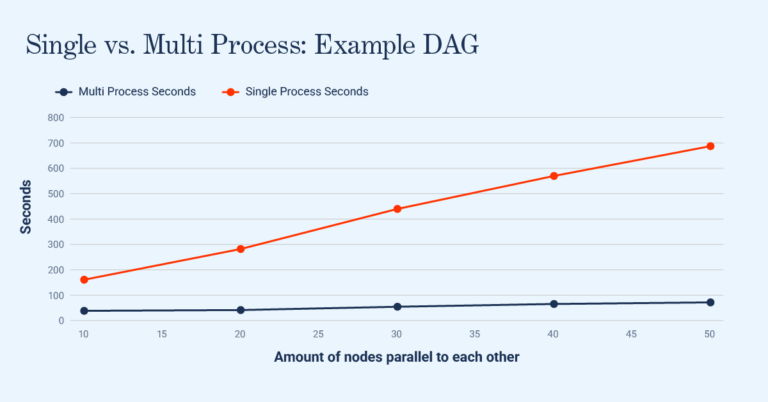
The shape of the example DAG used in this benchmark is “ideal” and aimed to show the best-case optimisations for the multi-process scheduler. However, it appears as a common type of sub-DAG in real examples, so benchmarks on real (more messy) DAGs converge towards this one. After this, I decided to test the scheduler on a real script used by our Single Stock Options team. When using a single process, it would take 78 minutes to start up and generate a single live value. Using the multi-process scheduler with a relatively simple partition of the DAG across processes, it took 16 minutes. These examples pave the way to bringing the scheduler into production usage on scripts that can make use of it, leading to substantial efficiency gains.
Infrastructure as Code with Terraform and AWS
Anita Sledz, University of Warsaw

Challenge
Working at Optiver, software engineers encounter multiple interesting problems daily. In the Infra Enterprise team, we are responsible for providing reliable infrastructure for software engineers, traders, researchers, and other teams.
During my internship, I was tasked with improving an existing infrastructure setup for an external-facing application requiring high availability. The goal was to free developers from concerns about the application’s connectivity, security, monitoring, and reliability.
Approach
My project involved using Infrastructure as Code and Terraform to provision the application platform infrastructure in AWS. The first step was creating a base infrastructure, starting with the establishment of a VPC – Virtual Private Cloud. Within this VPC, I created public and private subnets in different availability zones. By launching nodes in multiple availability zones, we aimed for the highest fault tolerance. Applications were to be deployed within these subnets. For enhanced functionality and security, I integrated NAT Gateways, route tables, NACLs, and WebACLs.
Next, I focused on the application infrastructure. For each application, I implemented code to provision an autoscaling group, which is a collection of EC2 Instances for app hosting. As implied, these can scale up or down based on load. There are health rules that trigger if the CPU usage goes over a certain percentage, leading to the launch of a new server. These instances are then connected to load balancers, distributing traffic amongst them. The load balancers use a sticky round-robin algorithm, ensuring that end users can access the application continuously. This is further supported by employing a rolling deployment strategy for all servers.
This approach was notably different from the previous one, where Elastic Beanstalk, an existing AWS service, was used. Instead, I opted for a method that offers more configurability and flexibility. I created Terraform modules that could be reused for other product infrastructures in the future. Additionally, I implemented a CI/CD pipeline to automate the provisioning of infrastructure to the cloud.
Results
After implementing the deploy pipeline, the system was ready for migration to production. This project highlighted the importance of understanding infrastructure challenges. It reinforced the idea that infrastructure serves as a foundational tool for other teams and that the reliability of this system has a direct impact on their work.
Let’s make automation scalable
Andreea Nica, EPFL

Challenge
Configuring our autotrader components in production is always challenging, due to many upstream dependencies and performance requirements. Moreover, more often than not, manual work is needed, making the whole process time-consuming and error-prone. In our trading operations team, we have build an automation tool to generate all the configuration files required for a specific autotrader in a reliable way.
In my project, I was tasked with devising a design solution for automated configuration generation that can be extended to many other autotraders.
Approach
The design stage was fundamental and was consolidated by a lot of research, understanding the differences between components, the limitations of current configurations structure, and how my tool can compensate for the lack of standardisation between different components. It was enlightening to talk to different developers and understand the reasoning behind their decisions and how these align with Optiver’s goals.
As part of my project, I also had to contribute to an already existing library, used by many other tools. The impact of my changes wasn’t only limited to my project, but could potentially touch other tools and components. Being able to see how meaningful my work was to the company truly was an amazing experience, as I felt confident taking ownership and leading the direction where I thought the project should be heading.
Implementing the tool itself proved to be a continuous improvement process, where feedback was integrated to enhance the quality of the results. With the support from my mentor and other team members, I was able to quickly execute and deliver multiple prototypes that guided further development.
Results
The end product is a command line tool that configures autotraders automatically, generating all the necessary files in the production configuration repo. Its standout feature is its adaptability: the tool isn’t just limited to one specific type of autotrader but can be extended to many others. It achieves this by decoupling the format structure of a component from the process of collecting the requisite information for the configuration files.
The technical challenges made the project truly interesting: having to learn a completely new language generator, using my creativity and critical thinking to determine the best design for the tool, deep diving into existing code to make a meaningful contribution, while also learning about Optiver’s infrastructure. One key takeaway is decisions should be made with the trading problem in mind, establishing the main priorities and objectives. And, in the end, with the right mix of these ingredients, even making automation scalable is possible.
Rewriting the IEX IML: A deep dive into low-latency trading systems
Alexandre Hayderi, University of Stanford

Challenge
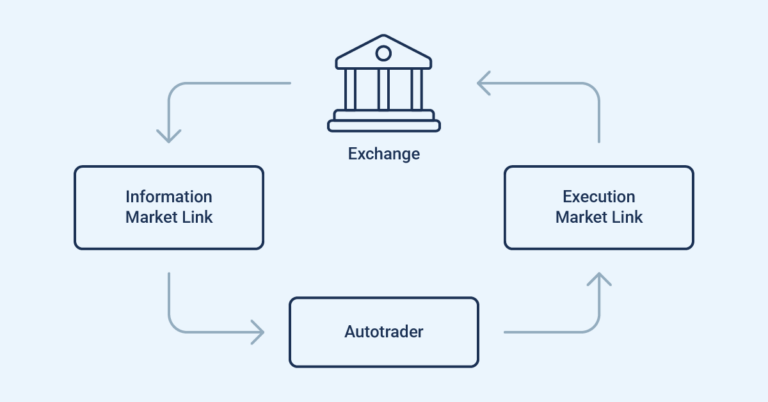
During my summer internship at Optiver, I worked on a really interesting project at the intersection of tech and trading: rewriting the Information Market Link (IML) for the Investors Exchange (IEX). At its core, an IML is a component that connects to the exchange and processes all incoming exchange-generated messages. Each exchange has its own unique message types and formats. IML translates this exchange-specific language into a unified language for our autotraders to consume. Due to the speed at which this process has to happen, the programming for this project was done in low-latency C++.
Historically, IMLs for various exchanges were developed independently, each bearing its own distinct architecture. However, this approach has many drawbacks and the team I was a part of developed a new, standardised structure for IMLs for better internal code sharing and reduced onboarding time for new IMLs. Beyond this, there are also some intrinsic latency advantages to the new structure.
Results
In the final week of my internship, I deployed my IML to production! This means that it was directly connecting to the exchange feed and forwarding messages to Optiver’s autotraders. Not only that, but my new version managed to reduce latency by 25% to 50%, as demonstrated in the graph below, with the new IML depicted in red and previous versions in contrasting colours.
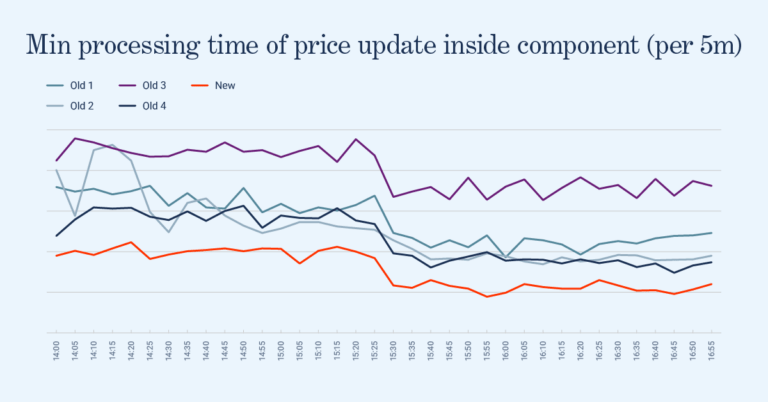
Overall, I found this project very interesting. It was my first time working on a component where low latency is a priority. It also allowed me to gain insight into Optiver’s trading infrastructure and to learn directly from traders about how they interact with tech systems like the one I was working on.
Are you our next intern?
Apply now for our 2024 Amsterdam internship program and get ready for an 8-week immersive learning experience.





